
Training the models behind the latest AI powered app, chat or co-pilot we are using with increasing frequency takes an incredible amount of data. Just where does all that data come from? An effort from the Data Provenance Initiative a volunteer effort audited over 4000 sources used to train AI models to determine their origins. They provided the data to be analyzed by MIT and a recent story by the MIT Technology Review provides interesting insights and trends.
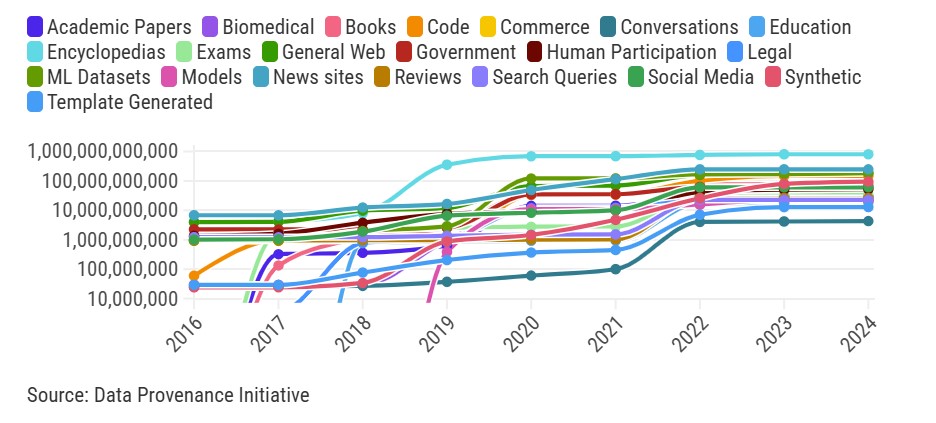
A lot of the usual suspects are prominent and share one common trait: they are openly available on the web. These sources range from the obvious ones like academic papers to a those we might overlook, like transcripts from a company’s latest earnings call. The article goes on to point out that one of fastest growing sources is largely under the control of one company, Google. Why such concentration with one company? In a word, YouTube. It seems that the rich video content that is accompanied by transcripts of every word spoken in every video is a very attractive resource.

Which data is being used by which models? How do the sources behind ChatGPT compare with those behind Google’s Gemini? We don’t know. The AI companies don’t normally share what data they used to train their models. If a particular data source generates a competitive edge they would want to keep that under wraps. The other reason is that they may not know either. With loads of data sucked in from the internet overall it is likely that the specific rights, licenses and copyright on all of that content are all a bit murky.
One source that is not opaque is the stuff we upload ourselves. The rights of the provider such as ChatGPT are clearly spelled out in this situation. The use of your data and content are handled by their Privacy Policy. This policy is extensive and we encourage actually reading it in full.
Two approved uses under this policy are worth highlighting.
1. Provide, analyze, and maintain our Services.
2. Improve and develop our Services and conduct research.
This essentially means you are giving them explicit permission to use your personal data for their own purposes. You can opt out of some of this permitted use if you are using a paid service, but it is not easy. A recent help article makes it a bit clearer if you want to dig in.
These AI tools are ridiculously useful when we are reviewing a contract, drafting a job description, or summarizing a dense paper we really don’t want to spend two hours reading. As we learned when smartphones and mobile apps first showed up, what starts at home soon shows up at work. These AI tools are even more useful in many work situations than they are at the house.
So how do we provide our employees the productivity tools they want while protecting our company’s proprietary data? Most of the large AI providers offer a clear solution, use an enterprise service. For OpenAI which is likely the first go to for your employees today, they spell out these protections very clearly in their Enterprise Privacy Policy.
Still looking for your first AI use case or wondering how you are going to integrate these tools into your workflows and don’t know where to start? Perhaps start with securing your data while providing employees with the tools they want and are likely already using. Once your data is secure and your team is free to experiment, learn and play, try your first use case automating a sticky process or building advanced forecasting. Once you get started the many opportunities will be fairly obvious.
(At NewTide we access the AI services from OpenAI or other providers using only their commercial API’s which provide clear Ownership, Control, and Security for our customers and their users.)



